Top 3 Tips To Turn Your Newsletter Into a Revenue-Generating Machine (and take back your relationship with your audience/subscribers)
Brought to you by Vubble's new RevLetter Get your data in order What data do
Some people talk about artificial intelligence as a ‘black box’. At Vubble, there is no such thing. Here’s Mariah Martin Shein, Vubble’s Director of Machine Learning, with an inside view.

The Vubble Recommender Engine is a versatile, modular and robust system for generating relevant, interesting and surprising content suggestions. It can provide recommendations within any of our Vubble products; it can also hook up to other platforms to provide recommendations for a diverse array of content, whether video or text, entertaining/educational, heavy or uplifting… (our journalist-annotated list of data labels runs more than 550 elements long).
The Recommender Engine is a critical component of the Vubble platform. It extends the functionality of our base A.I. system and the way we’ve built it makes it easier for our technical team to develop, test improvements and reiterate based on what we learn.
Looking at the Recommender Engine from an outside perspective: it’s simply a system that you can ask to make recommendations for a specific user, and it gives you back a list of content suggestions (all media content is possible, Vubble’s current focus is news/information video).
Here’s what that looks like:
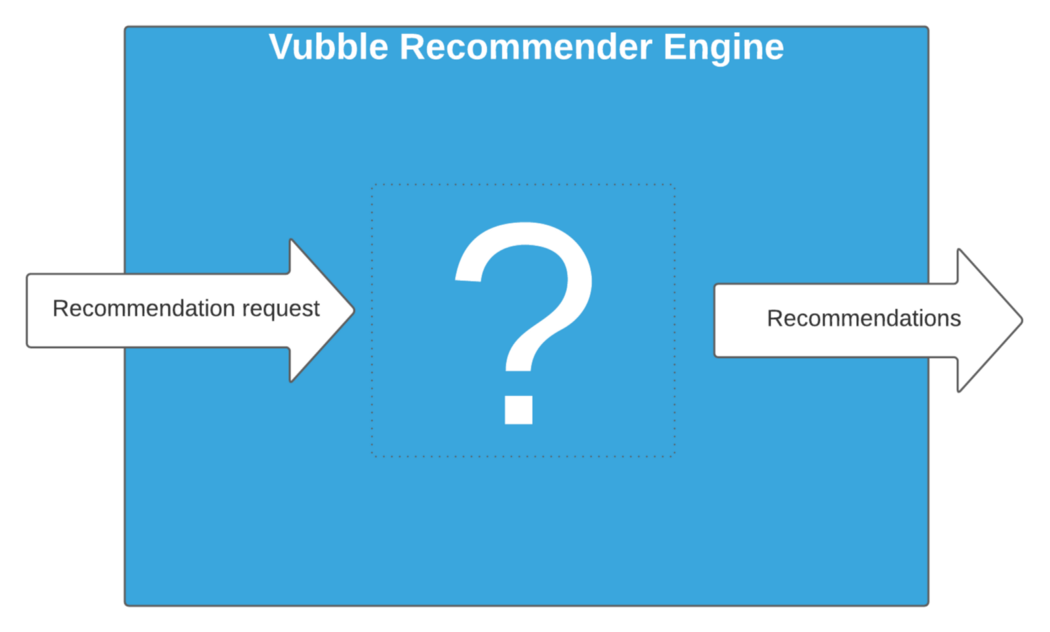
Simple, right? Let’s take the lid off and see you how those recommendations are made (things are going to get a little complicated, grab a cup and stay with me).
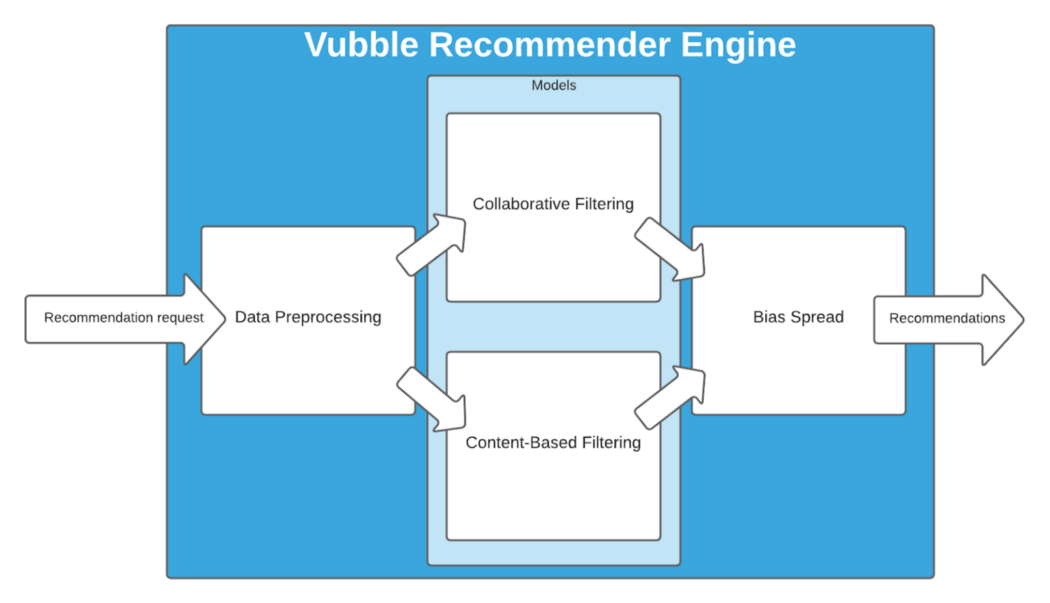
Think about the inside of the box in three parts: the data preprocessing, the machine learning (ML) models, and the bias spread algorithm.
Information flows through the system in that order: first preparing the data for use by the ML models, then the models generating recommendations, and finally the bias spread algorithm combining the recommendations in a way that aims to lift critical thinking (In some usecases, particularly news and information video content, it’s important that the recommendations not only be aligned with previous user behaviour — Vubble’s ‘bias spread’ algorithm aims to correct for bias by nudging users towards content that may be slightly outside their past interest sphere).
I’m going to talk about the three parts of Vubble’s (not-black) box in a slightly different order, however, because it makes more sense to explain the whole system by starting with the most fundamental component, the machine’s core.
1/ Machine Learning Models
The middle box of the diagram holds the machine learning (ML) models. This is where the artificial intelligence of the Vubble system resides. The ML models are the most essential components because without them, we can’t have any recommendations.
The Recommender Engine is designed to be able to use any kind of ML algorithm that creates models capable of making recommendations — and it can have more than one such model making recommendations in parallel.
These models tend to fall into one of two categories: collaborative filtering and content-based filtering.
Content-based filtering makes recommendations based on a user’s explicit preferences. When a user first starts looking for video recommendations in any of our Vubble products, they are asked to pick some categories that they’re interested in. Then, a content-based filtering model picks out video content that best matches these categories. This type of model makes the best use of Vubble’s large, journalist-annotated data set.
Currently, we have implementations of content-based filtering algorithms that create a model by representing every video in our dataset, and every user’s preferences, as a vector of categories. To get recommendations for a specific user, it calculates the similarity between that user’s vector and all the video content vectors using a metric called cosine similarity. Then it simply picks the top-most-similar videos to recommend. Of course, there are many other ways to do content-based filtering, and with this new Recommender Engine, other content-based filtering models can be easily added to the system.
Collaborative filtering makes recommendations based on a user’s past behaviour — which videos did the user actually watch and enjoy? When a returning user is looking for recommendations, a collaborative filtering model compares the videos they’ve seen to the videos watched by all the other users in order to predict what the user might want to watch next. For example, check out the table below. ‘1’ means the user is interested in that video, and ‘0’ means they are not interested in it. Spaces with ‘?’ indicate that we don’t know if that user would like that content or not. If you were trying to guess whether Casey would be interested in “Kodak tries to reinvent after struggling to adapt”, would you recommend it?
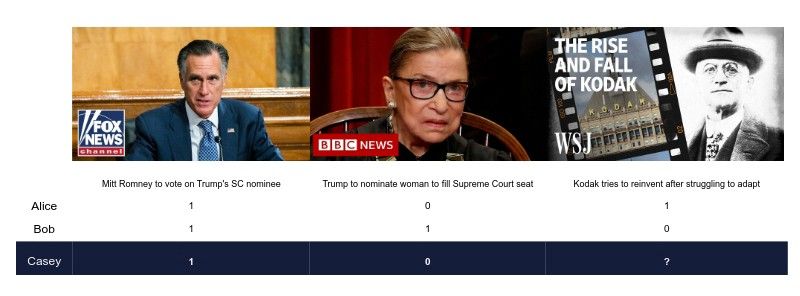
If you guessed that Casey would want to see it, you probably came to that conclusion in a similar way to a collaborative filtering model: by comparing what you know about Casey’s likes and dislikes to those of Alice and Bob.
Currently, at Vubble we’re using an implementation of collaborative filtering that makes use of implicit ratings. When a user interacts with a recommender system, they can indicate interest in content either through explicit ratings (e.g., giving it a score out of 5 stars) or through implicit behaviour, like which video out of a list they actually chose to watch. Using implicit ratings to make recommendations is generally considered to be at least as good as using explicit ratings, and has the added advantage of requiring less work from the user.
2/ Data Preprocessing
Each of these ML models needs data to learn, and this data needs to be in a specific format, based on the model. Content-based filtering needs to know content categories, but doesn’t care about user behaviour, and collaborative filtering is the opposite. So the first box in the diagram (“Data preprocessing”) represents the parts of the Recommender Engine that load in data from the main database and make sure it is in the right format for each model to use.
3/ Bias Spread
The final part of Vubble’s Recommender Engine is our bias spread algorithm. This algorithm does a lot of heavy lifting. It’s responsible for combining the recommendations made by the different ML models into one final list, and does so in a way that balances recommendations from each model while maximizing the overall diversity of the suggestions.
I claimed earlier that the ML models are the most essential parts of the Recommender Engine, for basic practical reasons. However, while it is not essential to making recommendations, the Bias Spread algorithm is arguably the most important part of the Recommender Engine, for two qualitative reasons.
First, one of the goals of Vubble is to “lift critical thinking”. A recent article by a researcher at Maastricht University suggests that encouraging people to engage with a wide variety of perspectives improves their critical thinking skills. Vubble’s Bias Spread algorithm maximizes the diversity of the suggestions in the final list in order to introduce users to ideas they may not have considered before.
Second, maximizing diversity in recommendations is also well-known to increase users’ interest and engagement in a recommender system. So the Bias Spread algorithm helps make the Recommender Engine’s suggestions more interesting to the user, while also encouraging them to push themselves outside of their regular thought bubbles.
The Recommender Engine is just one part of the Vubble platform. It works closely with our Recommendation Queue Manager, MongoDB database, and our backend API, all fully containerized and managed with Kubernetes.
I hope you’ve enjoyed this peek inside the box of the Vubble Recommender Engine. If you want to know more, feel free to contact me (mariah@vubblepop.com).
Stay tuned for another post that will take a look at the inner workings of the Recommendation Queue Manager!
© 2022 Vubble Inc. All Rights Reserved.
Home • Who We Are • Contact Us • Privacy Policy • Cookie Policy