Top 3 Tips To Turn Your Newsletter Into a Revenue-Generating Machine (and take back your relationship with your audience/subscribers)
Brought to you by Vubble's new RevLetter Get your data in order What data do
I failed to recognize BigTech’s Trojan Horse as it ambled through the gates of our information ecosystem in the days after September 11, 2001. But I strongly believe we can fix things now, if we work together.

September 11, 2001. Our world was reeling. We were drawn to our TVs, showing horrible scenes from Ground Zero in New York. Expert ‘talking heads’ gasped, nodded and filled the 24 hour news channels; car radios provided updates from political leaders as the ‘War On Terror’ began to take shape (“I can hear you!” U.S. President George W. Bush shouted into a megaphone, to a crowd gathered on the pile. “The rest of the world hears you! And the people who knocked these buildings down will hear all of us soon!”); newspapers printed extra editions, spilling barrels of ink to detail the latest investigations into the terror that had rained down on American soil.
For the news media, it was a pivotal moment, marking a shift in which the internet became the most powerful utility in our information ecosystem.
Re-read the first paragraph. I didn’t mention the web once up there. Not because it wasn’t already a dominant force in 2001, but because, for the most part, legacy media failed to take its “pivot to digital” seriously from the very beginning.
It is one of the greatest regrets of my journalism career that I failed to recognize BigTech’s Trojan Horse as it ambled through the gates of our information ecosystem in the days after September 11, 2001. But I strongly believe we can fix things now, if we work together.
Most of us didn’t have cellphones (it would take another year before RIM launched its first smartphone, the BlackBerry 5810, and Steve Jobs was still six years away from launching the first iPhone). Those of us who were trying to use the web to follow the news of 9/11 were probably using our desktop computers at work. The majority of us had our browser (probably Microsoft’s Internet Explorer) pointing to our favourite news organization as our ‘home page’ of the web.
We would start there.
It’s kind of quaint, when you look back with our 2020 vision today. On September 11, 2001, there was no Facebook for people to ‘check in’ on their loved-ones. None of it was captured on Facebook Live, because that didn’t exist (Mark Zuckerberg was just 17, not yet building the world’s largest data training set based on the actions of billions of people around the globe in real time).
There was no Twitter to scroll. User-uploaded video was not a thing — YouTube was still 3 years away. If you were a web-head, maybe you had a ‘weblog’, but most of us wouldn’t visit one of those until 2005.
Google was all about search, on the cusp of becoming the world’s predominant search engine (that would happen in 2002, 2004 if you’re a purist); but you had to know what keywords to search in order to find what you were looking for (over to you, Foucault).
Early search engines like Google’s literally indexed the web, which in 2001 was just over a billion pages of mostly HTML-coded text. Put into context, a media organization today probably has more than a billion “pages” of “content” within its own digital ecosystem.
Those early engines also made the choice to rank results by how many ‘other sites’ linked to them, placing the most ‘popular’ at the top.
<snark>Surely an infallible system! No one would create fake sites/people to inflate and skew this approach!</snark>
‘Popularity’ (or, data we agree is a signal of popularity?) won the day then, as it does now. The headlines we clicked on, the stuff we now “like” or retweet, our literal behavior and life on the web—where we go, what we linger over, how much we despise that actor’s haircut— these are all popularity data signals that BigTech has collected and built its business on.
Technology and storytellers are alike in that — we know there is tremendous power packed in our big emotions: anger, fear, jealousy and love.
That day, September 11th, 2001, woke Silicon Valley up to what we in the media business have always known: humans, with all our messy, beautiful, tragic, terrible and brilliant selves — when we get together, you can feel it.
If you’re a journalist at heart, I bet you want to use that energy in those big moments to help your fellow citizen better understand the world around them. I bet on those big news days, like September 11, your primary concern is how you tell the story as honestly and fairly as possible. The number of people you reach is secondary — but it is hard to resist the “views” count.
Back in 2001, as now, we humans did most of the work when using the technology platforms. We were, all of us, the real workers of the information economy, serving BigTech’s machines the minutiae of our moments— what we’re up to, where we’re going, what we’re interested in, what we’d like to spend our time (and money) doing — all enormously valuable popularity data signals when it comes to advertising.
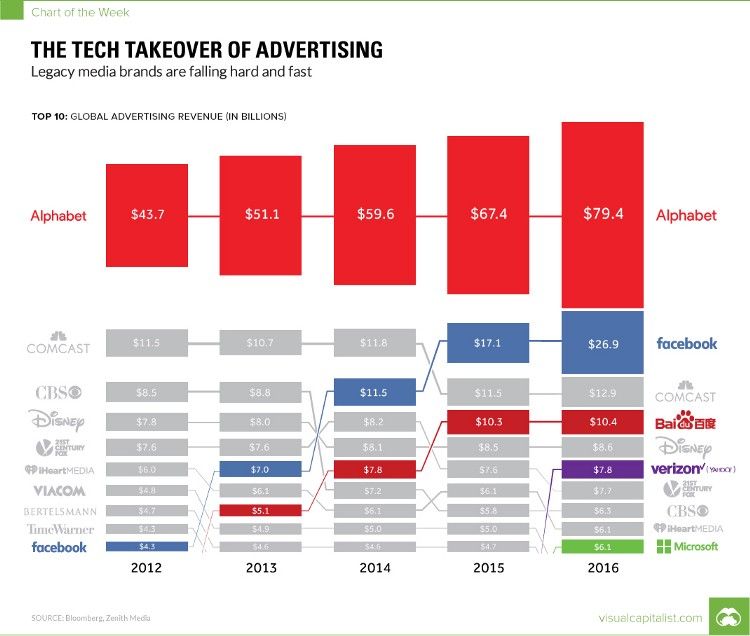
Our problematic relationship with BigTech’s approach to predicting what information we need to make sense of the complicated world around us … it started long before anyone had even imagined Instagram, TikTok, Facebook or the Russian Internet Research Agency.
On 9/11, I was in my mid-twenties, working as a digital producer for the Canadian Broadcasting Corporation for an investigative show on CBC TV called Disclosure.
As Canada’s national public broadcaster, on September 11th — and for weeks after — CBC had a massive problem. Canadians could not access our homepage, CBC.ca, because too many people were trying to open it at once. Remember, this is before social media and Google News. People came to the news brand they trusted and made it their homepage; our servers at CBC.ca were simply overwhelmed.
Despite being the oldest, most trusted and farthest-reaching network in Canada, and despite how the internet was already the dominant news delivery platform for my generation, we couldn’t make the internet work for us or our audience — Canadian citizens who needed quality, trustworthy information. We were journalists failing to get the story out.
If you’ve ever seen a movie about journalism, you know that’s not how the story ever ends.
Looking back, I believe September 11th was a watershed moment, when the media ecosystem moved from an analog, broadcast model towards a digital —and ultimately, AI-reliant pillar of the information ecosystem.
The trouble is, BigTech got there first. And we helped them; by not pulling up our sleeves and doing the difficult business of figuring out how to effectively use technology to distribute our content, ourselves.
Today, we’re facing an even more powerful entrant in the newsroom, AI, and we must get it right or risk the information economy being defined by again BigTech — not to mention authoritarian tech. When I say that, I’m not just talking about what’s going on in China; there are many examples closer to home in places like the criminal justice system, migration policy and “smart city” building. We need to get much better at defining how, where, why and when we enlist the help of AI in the crucial decision-making of our lives.
From the mid-90s until September 2001, the web was largely a ‘nice to have’. When it came to infrastructure spending at most media companies, faced with a decision to invest in a new suite of cameras for the field or a robust server farm, investing in the tools of creation would win every time.
At CBC, we had managed traffic in the thousands, occasionally hundreds of thousands. In the days after September 11th, millions were trying to squeeze through a pipe that simply wasn’t equipped to handle it. (The nostalgic in me imagines some of that traffic getting stuck in the original server built by a CBC Radio technician in a closet in the early 90’s — the original host of CBC.ca.)
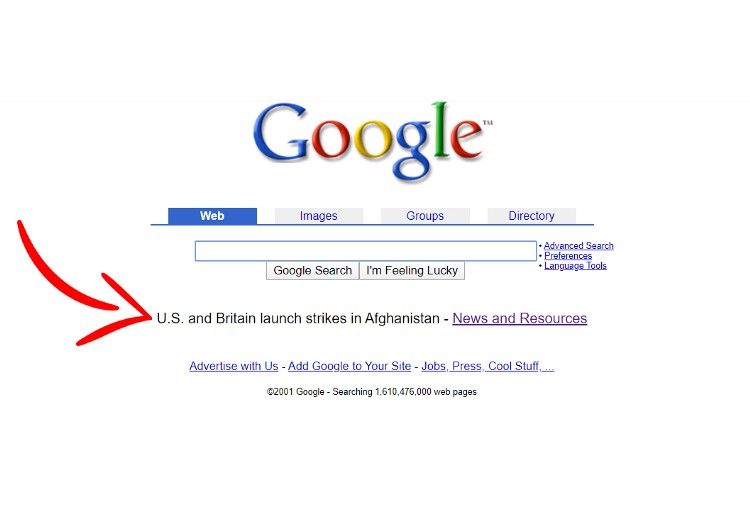
The CBC’s patchwork, online server infrastructure was no match for the the traffic from the events of September 11, so we called Google.
CBC News joined other media organizations — Canadian, American and international — with a simple ask: if we send Google direct links to the most important articles on our websites, could Google list direct links on its homepage? (It’s a process I’d initiated with Yahoo! a few years earlier when I ran CBC’s first online arts and entertainment news portal, Infoculture.)
“Human-in-the-loop” intervention by journalists was something the tech platforms needed and wanted. BigTech needed help putting context around the relentless barrage of news; they needed us to tell them what our stories were about, feeding data signals into their systems.
Our servers were melting. Google had the server heft, and 9/11 search queries dominated their interactions — everyone would win if we could just work together.
And there you have it — the origins of Google News.
It was an invention of the best kind — made out of necessity. At CBC, we had digital line-up producers emailing contacts at Google with suggestions for news articles they should link to (my now Co-CEO/Co-Founder at Vubble called home to tell her parents when her biography of Osama bin Laden was featured on Google.com). The headlines and links went up, and Google came back for more.
For a while, it worked like that — we’d send links and mostly Google would list them. Then, as the news cycle pushed on, we went back to what we do, as journalists: getting the information, putting it together, getting it out there.

The trouble is, legacy broadcast networks like CBC were so invested in old infrastructure (and for some, bountiful advertising revenue), we let go of the ‘getting it out there’ piece.
This lack of innovation and imagination for how audience behaviour was changing was exploited with tremendous effect by the social media platforms that emerged in the years that followed with the rise of “Web 2.0”. And it was exploited again by dark players who would later weaponize the frailties of those same platforms to wreak havoc on elections, human rights and ultimately our understanding of ourselves.
Getting trustworthy, quality news content in front of citizens who need to see and understand it is not a new thing. It is a core mission of journalists and the information media ecosystems of every democracy on Earth. We should have done better back on 9/11, and we must carefully consider our approaches to digital distribution now as artificial intelligence automates editorial functions in the newsroom today and tomorrow.
In the fall of 2002, Google officially launched Google News — a technological solution to the problem of ‘how can we help people find meaningful, relevant information on the web?’ It was a problem legacy media had failed to address, handing it to BigTech to manage. And they did.
An interesting side-note: Google News was followed by Gmail (2004), Google Maps (2005) and YouTube (2005). Google News was a precursor to all of it. Tech companies like Google could see where conventional media was failing the emerging digital audience in 2001, and they filled that void.
To their credit, they made it better — and for a time, the tools Google (later joined by Facebook, Twitter and the whole FAANG squad) came up with were irresistible to legacy media as we tried to sort out this “internet thing”.
Google News was digital publishing on steroids — it was super efficient. If you could get your article listed (it was pretty much only text back then), you got audience to it. Exponentially bigger audience numbers were coming directly from the BigTech platform referrals, eclipsing the traffic a media company could achieve alone.
Then, Google did what all tech platforms do — they began automating their systems; at CBC, we had fewer and fewer opportunities to connect with the Google people to pitch for our articles to show up — and eventually they just stopped answering the phone and responding to our emails. Eventually those friendly Google people we’d dealt with in the early days after September 11 were replaced by algorithms to read, prioritize and distribute our articles — serving millions of people at click of a mouse, something we simply couldn’t do with our “legacy” systems.
Algorithms, machine learning, the functioning processes of AI — they can only work with the signals we provide them. We give a few instructions, and based on those signals, the machines make predictions — and ultimately they will make decisions (if we let them — we really should be more careful about when that should happen).
The earliest versions of Google’s own search system relied on “regular people” like you or me, helping to identify the content of a web page and the topics it covered. For example, DMOZ, a collaborative editorial project, played a significant role in helping Google understand what websites of the day were really about, by enlisting an army of human volunteers to annotate and validate the context of what a web page might be about. Because computers can’t really think.
Today, the world’s biggest technology companies are using thousands of human workers around the world to tell computers what to “think”. It is not exactly futuristic work. It is mundane but necessary data grunt-work; the manual annotation of content, data-tagging has exploded as an industry. Most tech executives don’t discuss the labor-intensive process that goes into its creation. But I will — and I will tell you that AI is learning from humans. Lots and lots of humans.

Before an AI system like my company’s can learn, people have to label the data it learns from. This work is vital to the creation of artificial intelligence used in systems for self-driving cars, surveillance and automated health care.
The market for data labeling passed $500 million in 2018 and it will reach $1.2 billion by 2023, according to the research firm Cognilytica. Data tagging accounts for 80 percent of the time spent building AI technology.
BigTech keeps quiet about this work; they face growing concerns about privacy and the mental health of “taggers” (cousins of the “content moderators”). At Vubble, we insist on using local journalists to data tag news video for some of the world’s leading news organizations. That’s because, as journalists, we know that context is everything, and humans still beat today’s earthworm-brain AI.
AI is great when we use it to spot a cancerous mole — it is mind-blowing that a machine can spot anomalies in thousands of images in a millisecond, something a human doctor, no matter how brilliant, could ever do.
Er… hold on! Here’s an AI engineer from Google itself, telling us that the human doctors out-performed the AI in some cases too. He ends by saying AI is best in complement to the human brain. We lift each other up.
Today, we need to work together, with machines, in ways we have never worked before. If you stop reading here, I just ask as that you keep this in mind: We all need to think carefully about how we work with AI going forward. The decisions we let AI make on our behalf are based on the signals we give it to base those decisions on.
(2/4 — In the next section, we’ll did into the weaknesses of AI, and how that’s opening up new opportunities for the news media industry)
The way we talk about AI is full of hype. We’re really only at the beginnings of the beginning of AI and its intersection with humanity. It is doing some incredible things right now. It will do absolutely remarkable things in the future, I’m sure.
But right now it’s about as smart as an earthworm. (That’s a favourite analogy of AI researcher Janelle Shane, author of the hilarious and telling book, “You Look Like a Thing and I Love You: How AI Works and Why It’s Making the World a Weirder Place”, which documents how AI can do some ridiculously awful things — while showing us who we are in the process.)
In my couple of decades as a journalist, and as a human growing up in the time when a computer went from a “business machine” (this was the first computer I used in my grade 6 ‘computer lab’) to a personal AI butler in your pocket in less than three decades, I’ve learned that technology really only moves as fast as we do. But sometimes it feels like we’re not going in the same direction. We all need to pay attention and know when our paths diverge, especially if you’re already using AI in your newsroom or as a tool for content recommendation.
It’s difficult, but not impossible, to come up with signals about complex and evolving news stories. But we need humans, journalists, to teach the machines when it comes to information content.
This has become the core issue of our lives today, because the unexpected is our new normal. The world has gone from being complicated to being complex. There are patterns (which machines can spot and identify), but they don’t repeat themselves with regularity (confounding those same machines). And so much of our world defies forecasting now. Maybe Iran will retaliate against the USA, but we don’t know why or when and whether it will be physical or cyber or something else. Climate change is real, but we can’t predict what will happen in Australia’s bush-fire crisis, and what the impact will be when climate migrants begin to move in significant numbers. Brexit may finally happen. Or not. And we’re all at the mercy of one guy’s Twitter quips from the White House (remember when “microblogging” sounded cute?).
Uncertainty rules the day. The “news”, what is happening and what might happen next — it defies so much forecasting, efficiency doesn’t help us, it specifically undermines and erodes our capacity to adapt and respond.
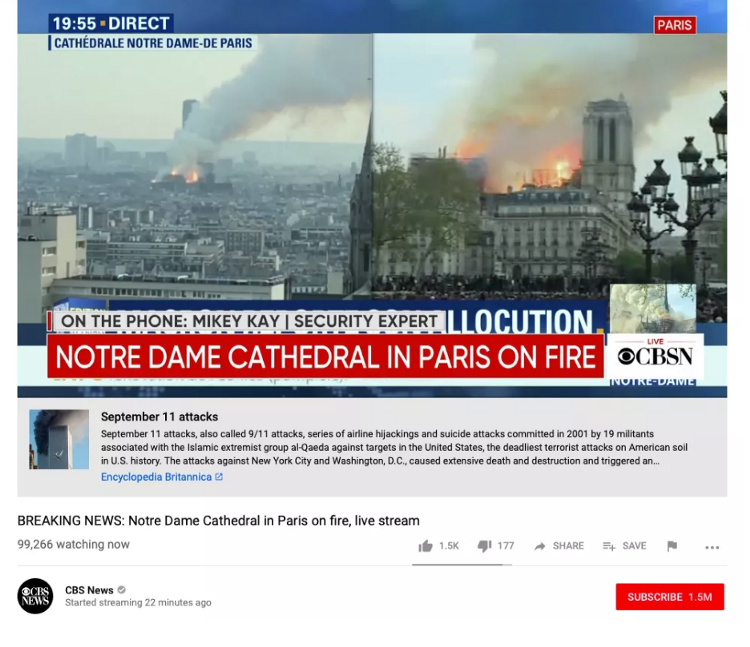
I have had this feeling before. Maybe you have too. To me it feels exactly like the days in and around 9/11 — and I’m feeling a warning coming on: when we abdicate responsibility for understanding the complex issues of our day to technology, it makes mistakes.We make mistakes. Like Google’s own algorithm that began recommending stories about 9/11 to citizens watching footage of Paris’ Notre Dame cathedral ablaze on April 15, 2019.
What irony — watching Google’s own tagging training set provide the basis for inaccurate and outright stupid recommendations on Google’s own video platform, at a time when people need access to reliable, factual information.
But hey — It’s going to be okay. That’s why we’re in this business. We journalists roll with uncertainty. We literally work to find the facts amid ambiguous noise to help our fellow citizens understand what’s going on today. That’s our job. We do the work that AI needs most now. Structured, reliable, dependable data that a machine can learn from: it is the foundation of AI.
And the great news is that when it comes to “ambiguous” information content — that structured data belongs to all of us.
We just have to keep it that way.
Our world is awesome, chaotic and confusing. The complexity of human life is more than the 1’s and 0’s a machine can understand. When it works well, AI can very quickly perform repetitive, narrow and defined tasks.
When you’re working with AI, it’s not like working with another human, it’s more like working with some weird force of nature. It is really easy to give AI the wrong problem to solve. We as humans aren’t always great at defining a narrow problem, because our brains are wildly complex. Our brains do a lot of really broad, advanced problem solving without us even noticing.
Chess is a complicated game. But it’s also based on rules, logic and probability. Machine learning can handle that, and while it surprised many when a supercomputer named Deep Blue beat world chess champion Garry Kasparov in 1997, it makes perfect sense that a machine could learn from our moves and mistakes and ultimately kick our pants in an even more complex game, Go, in 2016.
Is playing a game of chess more complex than doing the laundry? You might say yes, but let’s dive in for a moment. What about the different fabrics? Can they all be washed the same way? Sure, you might be super high-tech with your smart-labelled clothes, but what of the items that don’t? What about the colours? Your kid’s tie-dyed shirt from camp, can that go in? Where did that other blue sock go?
What we might consider the simple chore of doing laundry is actually a much more complicated task than at first glance. (Incidentally, I would be remiss if I didn’t take a moment to flag that there are some problems tech just doesn’t need to solve for us. We need to get better at deciding when that is.)
This is why it’s so hard to design a problem that AI can understand and make dependable predictions and recommendations on. This problem gets infinitely more complicated when we’re dealing with video.
The AI that’s used to recommend video content on YouTube and now by some media publishers for their own information video, these algorithms are optimized to bias in favour of clicks and views — popularity signals are the main drivers of recommendations, because more clicks and views means more exposure to advertisements, the revenue source of most content publishers and the BigTech.
But here’s something we know about humans. Content that is sensational, that makes us angry, that kind of content really fires us up — we click, we comment, we share, we give that content a lot of our attention. Our engagement behaviour around that content, in turn, provides signals to the machines recommending it, amplifying its spread. This is why within a few clicks, you’ll likely be recommended misinformation, conspiracy theories, and worse. The AI itself doesn’t have a concept of what this content is, or what the consequences might be for recommending it. It’s just recommending what we’ve told it to.
(3/4 —In the final section we’ll explore a narrow opportunity we have at this very moment to bolster the world’s information ecosystem, putting us, curious, thoughtful human thinkers at the centre again.)
We as humans have to learn how to communicate with AI. We have to learn what it’s good at helping us with, and what it might mess up if we’re not watching it.
The role of the modern digital citizen of a democracy has become similar to the old-school editor — knowing where a piece of information came from, assessing its credibility and potential biases, framing it within the context of the rest of the information of the day.
There is simply no substitute for human judgement. Algorithms making decisions need to be audited to help us uncover biases (unintentional and overt), and if there are biases, how our AI systems can be adjusted to limit their impact.

The role of the modern provider of news and information media is to know how AI is being used to distribute your content. It is our absolute responsibility to know exactly what instructions our machine learning systems are basing their predictions on. We must also know what training data set our AI is using to learn from; where that training set may be thin, where it may lack diversity in its examples; how it can be improved upon to deliver the right content recommendation to the person who needs it when they need it.
There is simply too much at risk, and tremendous opportunity missed, if we don’t.
Beware of the hype. Today’s AI is not super-competent and all-knowing. Everything AI knows is what we’ve told it. And right now, the media industry has fallen behind in helping AI help us when it comes to news and information content.
BigTech marketers would like us to believe that AI systems are neutral, highly-intelligent and sophisticated. But we simply aren’t there yet. The tech world gets excited about things like “big data” and “data as the new oil”. It kind of is if you only think of it as a resource — which it is. But to my mind, we need to be thinking about it as a public resource.
Data signals can be used for good and for bad (intentionally and not). The same data training set could be used by medical researchers to uncover better diagnostic symptoms for a form of breast cancer — or used by an insurance provider to identify those customers more likely to contract that breast cancer. One machine learning system could use a training set to hire the best candidate for the job, another could unintentionally ignore female applicants because of a biased weighting in its machine learning logic.
Instead of throwing up our hands, we have a narrow opportunity at this very moment to bolster the world’s information ecosystem, putting us, curious, thoughtful human thinkers at the centre again.

We need to start with some grunt work: data-tagging. Creating structured data for information video content is not glamorous, but it is the building block of effective machine learning. Since 2014, my company, Vubble, has been doing the critical work of data-tagging news video from the world’s leading news organizations (including CTV News in Canada and Channel 4 News in the UK).
Using our unique ‘journalist-in-the-loop’ approach to annotation and our proprietary taxonomy created by journalists and library scientists, Vubble has created what we believe to be the world’s largest data training set for “ambiguous” information video content — the key to unlocking AI that can help us understand what’s happening in video, moving images, and even predicting what is happening in real life. (“Ambiguous” content is an AI term that refers to complex information that requires context for comprehension by humans, and is particularly opaque to the earthworm mind of current AI systems).
The AI systems that exist today, including Vubble’s, can only predict with slightly better-than-random certainty what is actually happening in a news video. But our AI is getting smarter every day, thanks in large part to the priority we put on transparency, human (journalistic) insight and oversight, and what’s called in the industry “explainable AI” (an emerging field in machine learning that aims to provide overt transparency, accountability and trustworthiness in AI systems).
Our AI has more to learn from every day as we continue to annotate information video from the world’s leading media publishers. In 2019, the Canadian government joined us to help, providing Vubble with funding via the Digital Citizen Initiative to subsidize our cloud-based data-tagging of the long-tail information video from Canada’s major news media companies.
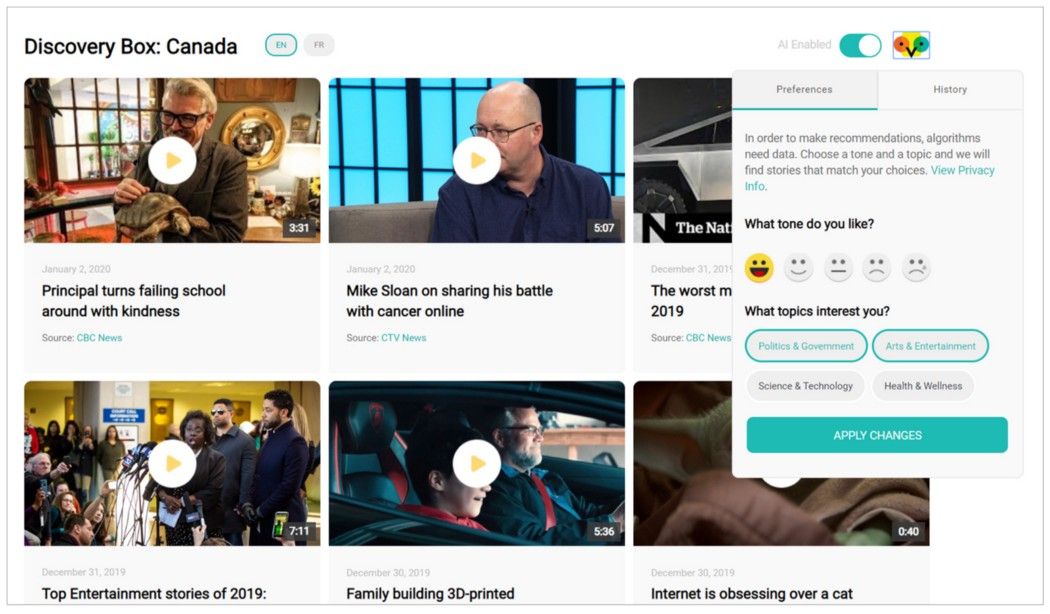
This month, we will launch a public-facing version of this effort, Discovery Box: Canada (scroll down a bit), a bilingual database of news video, filterable in three ways: linear feed, keyword search and an opt-in algorithm.
What we’re trying to do with Discovery Box: Canada:
In return, Vubble is providing Canada’s main news media publishers with the structured data our editors have generated around their news video. A must-have for quality, reliable AI recommendations, this structured data, if used thoughtfully and effectively, will help Canada’s news media as they move from conventional print and broadcast distribution towards AI distribution, ready to make powerful, reliable content recommendations and get the right information in front of people who need to receive it.
In 2020, it is Vubble’s mission to help Canada’s news media break through the barrier of weak and unstructured data, while building the world’s largest, context-rich data training set for teaching machines to provide top-quality, reliable recommendations at a mass scale.
We’re passionate about the innovation, research and development possibilities that promise to grow from here — from using the Vubble training data set to help companies predict changes in audience usage behaviour, to automating the real-time mass delivery of critical news information across platforms and devices — we’re pulling up our sleeves, developing new distribution tools to meet Canadians where they are, with their needs at the core of our decision-making.
Not long ago, the media industry woke up and realized that we no longer own our relationship with our customers. We no longer run the distribution business that generates profits from our work, and most of us don’t own the relationship with the technology to get our stories out there. When that first Trojan Horse rolled into our industry in the days after September 11, 2001, we began to cede virtually every facet of our industry to BigTech.
No more.
The news media’s relationship with the citizens of our democracies is a partnership — one that requires trust, respect and transparency as AI enters the newsroom. We have a common goal: to help citizens access trustworthy, factual information when and how they need to receive it.
As automation advances into the media business, particularly in the distribution space, it is the responsibility of our entire industry to ensure that we move forward together, in meaningful cooperation, to defray the power and influence of BigTech in the information ecosystem.
At Vubble, we’re committed to building strong and lasting collaborations within the news media around three things: providing structured data around your large libraries of information video content; continuing to build the world’s largest journalist-annotated information video training dataset; and being a ‘sandbox’ of AI R&D, where we can all work together to test new ML methods, try out new training models, and share new learning.
In 2020, if we can find ways to work together, the entire Canadian media industry will be better prepared for AI’s advance into the newsroom. The future hasn’t been written yet — a free and informed society depends on us pulling up our sleeves and getting into the hard work of rewriting our industry’s relationship with AI.
Because a healthy information ecosystem is the lifeblood of a functioning democracy.
(4/4 — Thanks for reading. If you have thoughts, get in touch. I’d love to hear from you!)
Tessa Sproule is the Co-Founder and Co-CEO of Vubble, a media technology company based in Toronto and Waterloo, Canada. Vubble helps media and educational groups (like CTV News, Channel 4 News, Let’s Talk Science) by cloud-annotating news video, building tools for digital distribution and generating deeply personalized recommendations via Vubble’s machine-learning platform.
© 2022 Vubble Inc. All Rights Reserved.
Home • Who We Are • Contact Us • Privacy Policy • Cookie Policy